Inhalt
Tutorial Videos
(Es gibt leider keine Tutorial Videos zu diesem Thema)
Bei der Bestimmung des Vorhersageintervalls haben wir mit der Näherungsformel ein Werkzeug, um die linke und rechte Grenze zu bestimmen. Damals mussten wir die reellen Werte der berechneten Grenzen runden, um das Intervall in der diskreten Verteilung festzulegen.
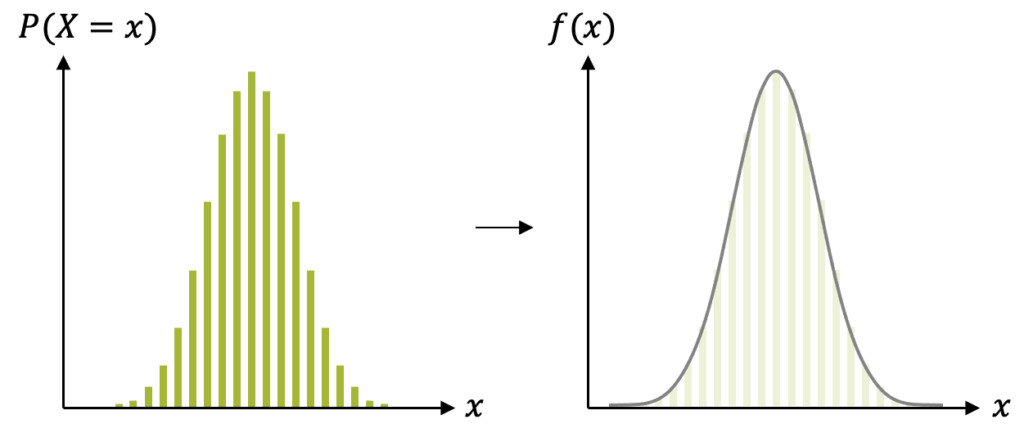
Wenn wir sehr grosse Stichproben haben (\(n\) sehr gross), dann hat die Wahrscheinlichkeitsverteilung sehr viele Säulen, die eng zusammenstehen. Ähnlich wie in der Integralrechnung, können wir uns vorstellen, wie für noch grössere Stichproben, d.h. für \(n \rightarrow \infty\), die diskrete Wahrscheinlichkeitserteilung \(P(x_i)\) in eine kontinuierliche Verteilung \(f(x)\) übergeht.
Für die Berechnung von Erwartungswert \(\mu\) und Standardabweichung \(\sigma\) (bzw. Varianz \(\sigma^2\)) benutzen wir ein Integral statt einer Summe:
\[ \mu = \sum_i \Big( P(x_i) \cdot x_i \Big) \quad \rightarrow \quad \mu = \int_{-\infty}^{\infty} f(x) \cdot x \; dx \]
\[ \sigma^2 = \sum_i \Big( P(x_i) \cdot (x_i-\mu)^2 \Big) \]
\[ \rightarrow \quad \sigma^2 = \int_{- \infty}^{\infty} f(x) \cdot \big(x – \mu \big)^2 \; dx \]
Die Glockenform der Binomialverteilung geht dann über in die sog. Gauss’sche Glockenkurve. Diese kontinuierliche Glockenkurve wurde mathematisch formuliert und wird Normalverteilung genannt. Sie ist eine gute Näherung für die Binomialverteilung für grosse \(n\), jedoch nicht für extreme Wahrscheinlichkeiten \(p\), d.h. nicht zu nahe am linken Rand \((p \approx 0)\) oder zu nahe am rechten Rand \((p \approx 1)\).
Nachfolgend die mathematische Formulierung für eine allgemeine Glockenkurve, die spiegelsymmetrisch bezüglich der \(y\)-Achse ist:
\[ \varphi(u) = \frac{1}{\sqrt{2\pi}} \;\; e^{-\frac{1}{2}u^2} \]
Die Binomialverteilungen haben jetzt verschiedene Erwartungswerte und Standardabweichungen. Um alle möglichen Binomialverteilungen mit dieser einen Normalverteilung beschreiben zu können, brauchen einfach die Normalverteilung entsprechend horizontal zu verschieben und seitlich zu strecken bzw. zu stauchen. Wir ersetzen dazu das Argument \(u\) der Funktion \(\varphi(u)\) mit folgendem Ausdruck:
\[ u = \frac{x-\mu}{\sigma} \]
Dieser Ausdruck wird eingesetzt und dann wir die neue Wahrscheinlichkeitsverteilung normiert, d.h. so angepasst, dass die Fläche unter der Kurve genau gleich 1 ist. Als Wahrscheinlichkeitsverteilung muss ja die Fläche alle Fälle umfassen und damit 100% Wahrscheinlichkeit entsprechen. Wir erhalten schliesslich:
\[ f(x) = \frac{1}{\sqrt{2\pi \sigma}} \;\; e^{-\big(x-\mu\big)^2 \big/ 2 \sigma^2} \]
Die Normalverteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung mit Erwartungswert \(\mu\) und Standardabweichung \(\sigma\). Ihr Verlauf ist eine Glockenform, deren linkes und rechtes Ende eine verschwindend kleine Wahrscheinlichkeit haben.
\[ f(x) = \frac{1}{\sqrt{2\pi \sigma}} \;\; e^{-\big(x-\mu\big)^2 \big/ 2 \sigma^2} \]
Die Fläche unter der Kurve entspricht 1
\[ \int_{-\infty}^{\infty} f(x) \; dx = 1 \]
Beachte, dass das Integral über die Normalfunktion nicht einfach zu bestimmen ist. Es braucht dazu Tabellenwerte.
Mitte des 19. Jahrhunderts befasste sich der Belgier Adolphe Quetelet der Statistik und untersuchte die Daten des Brustumfangs von fast 6’000 schottischen Soldaten. Dabei stellte er fest, dass diese Daten die Normalverteilung bestätigten, d.h. sie bildeten die Glockenkurve um den Erwartungswert herum. Quetelet gilt heute als Begründer der modernen Sozialstatistik und hat vermutlich den Begriff Normalverteilung geprägt. Auf ihn geht auch die Körperkennzahl BMI (Body-Mass-Index) zurück.
Mit der Normalverteilung war eine Funktion der Natur gefunden. Viele gemessene Verteilungen aus den Natur-, Ingenieur- und Wirtschaftswissenschaften werden durch eine Normalverteilung beschrieben. Damit hat die Wissenschaft ein mathematisches Werkzeug, um die Streuung von Messwerten oder chaotischen Prozessen zu beschreiben.
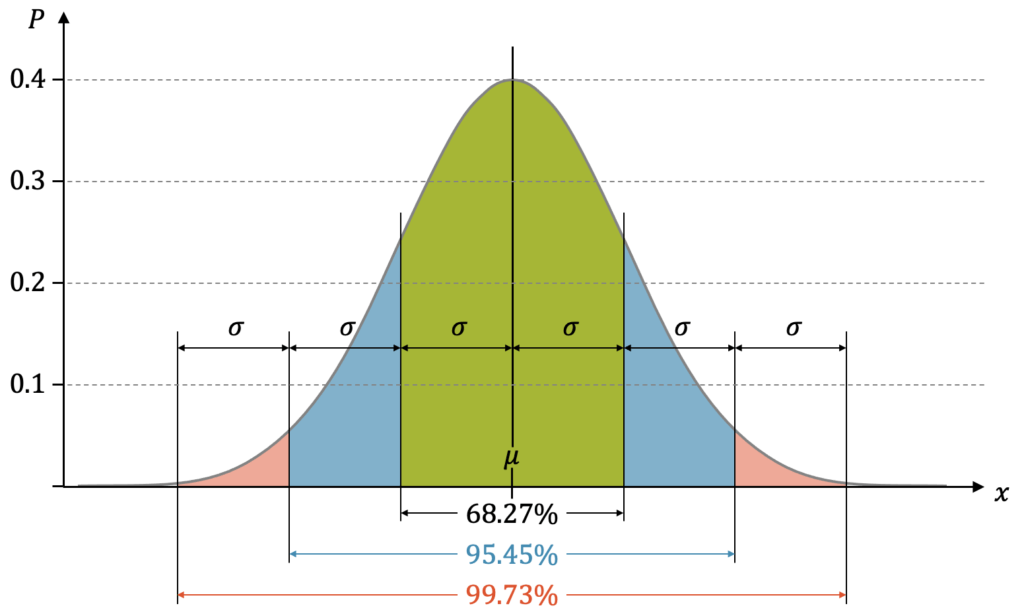
Vorhersageintervalle bei der Normalverteilung.
Das Intervall aller Ergebnisse mit einer Abweichung von einer Standardabweichung (“1-\)\sigma\)”) enthält 68.27% aller Ergebnisse, also rund zwei Drittel aller Fälle. Wenn wir vom 2-\)\sigma\)-Intervall reden, haben wir ein Intervall, das 95.45% aller Fälle enthält. Es entspricht ziemlich genau dem 95%-Vorhersageintervall. Bei der Breite 3-\)\sigma\) haben wir 99.73% aller Fälle.
Weitere Videos
(keine externe Youtube-Videos zu diesem Thema)
(keine Aufgaben-Videos zu diesem Thema)
Mini-Test
Um Zugang zum Mini-Test zu kriegen,
musst du vollwertiges Mitglied im Hacker-Club sein.

publiziert:
überarbeitet:
publiziert:
überarbeitet:
Schreib deine Frage / Kommentar hier unten rein. Ich werde sie beantworten.
Inhalt


Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.